
{kind=link}
About Me
Hey there! I’m Tianle Cai (蔡天乐, pronounced Tyen-luh Tseye), a PhD student at Princeton University, where I work with Professors Kai Li and Jason D. Lee.
Before Princeton, I got my undergrad degree at Peking University, majoring in applied mathematics and also double-majoring in computer science. Under the guidance of Professor Liwei Wang, I started my research on machine learning, an amazing realm. I also worked closely with Professor Di He.
During my PhD, I was fortunate to take a few part-time internships: at Google Deepmind under the guidance of Xuezhi Wang and Denny Zhou, and at Microsoft Research with advisors Sébastien Bubeck and Debadeepta Dey.
My academic interests span across a wide spectrum within machine learning, including optimization, representation learning, architecture design (with focus on Transformer, Graph Neural Networks, and so on), and more recently, system-architecture co-design. My overarching mission is to advance the generalization [1, 3, 4, 6], efficiency [2, 5, 8, 9, 11], and reliability [7, 10] of machine learning (please refer to my listed publications below).
If you share common interests, are interested in potential collaboration, or simply want to connect for a chat, feel free to contact me via e-mail or WeChat. I’m always open to conversation :)
News
- Starting a part-time internship at Google Brain! Jan. 2023
- My intern paper @MSR got accepted by ICLR 2023! Jan. 2023
- I’m working at Microsoft Research this summer! May. 2022
- Three papers accepted by NeurIPS 2021! Sep. 2021
- Graphormer wins first place in PCQM4M task of OGB-LSC @ KDD Cup 2021! June, 2021
- Three papers accepted by ICML 2021! May, 2021
Selected Publications
(Preprint) Large Language Models as Tool Makers
Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, Denny Zhou
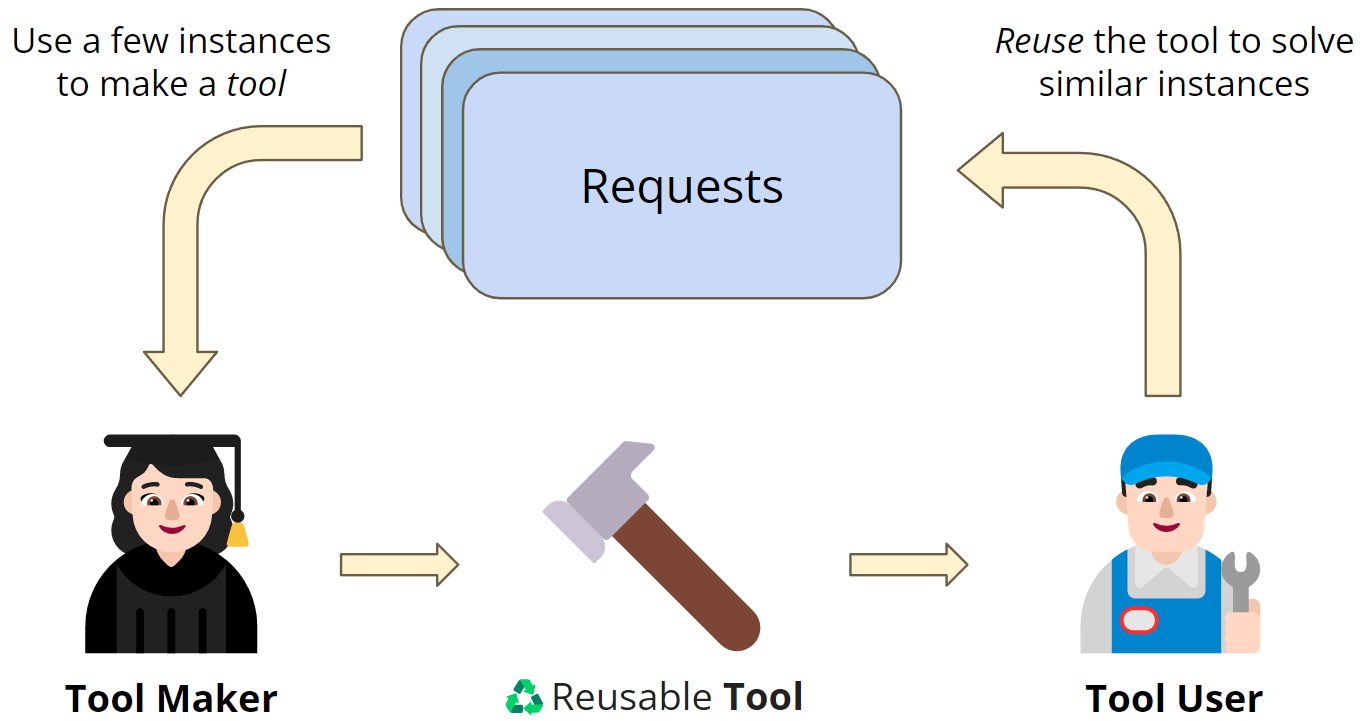
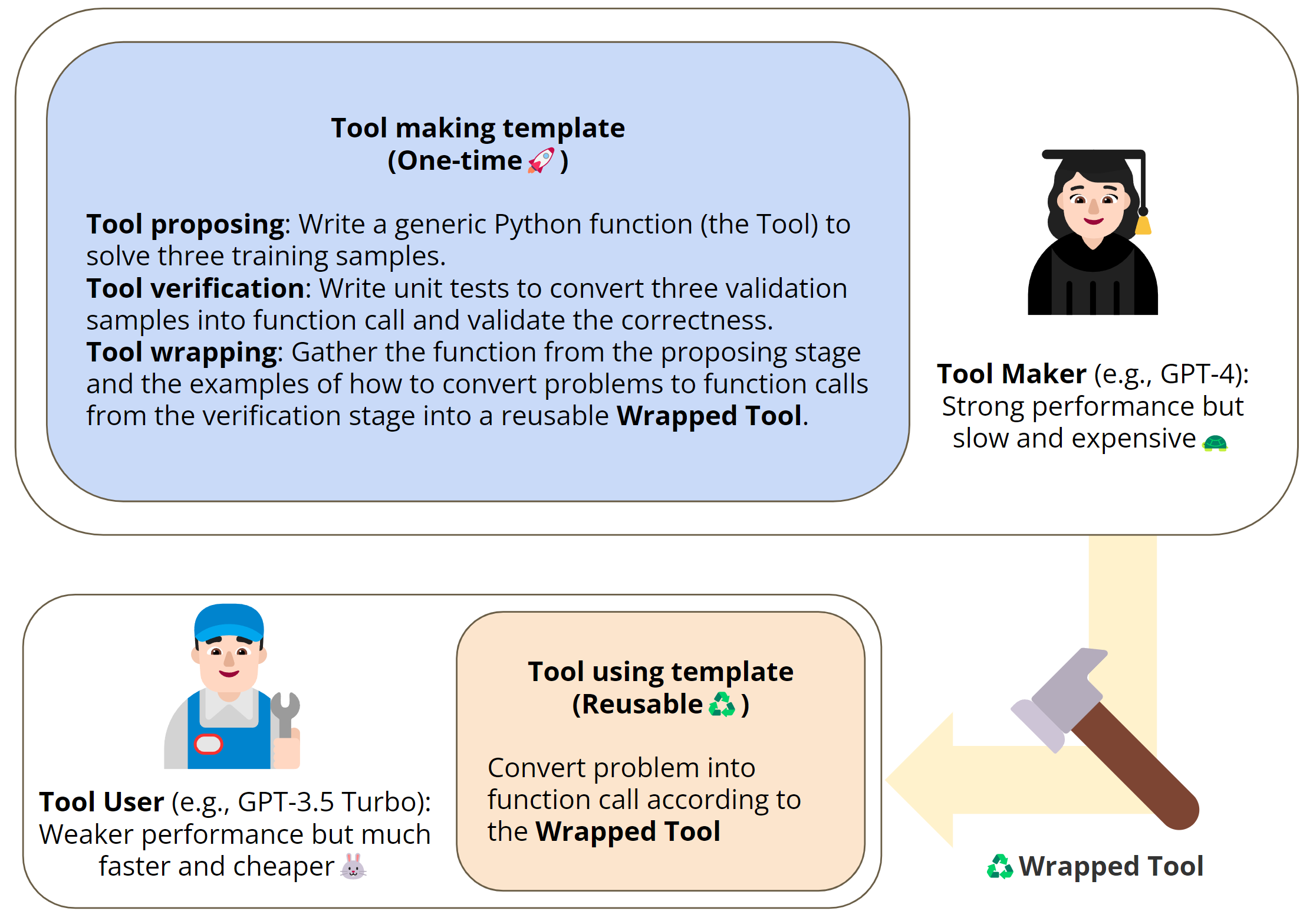
Highlight: Tools can boost the productivity of LLMs, but what if there isn’t a suitable tool?– Let LLM build their own We introduce “LLMs As Tool Maker”: one LLM serves as Tool Maker👩🏻🎓 to make new tools🔨, another LLM servers as Tool User👨🏻🔧 to solve new problems with the tool.
(ICLR 2023) What Makes Convolutional Models Great on Long Sequence Modeling?
Yuhong Li*, Tianle Cai*, Yi Zhang, Deming Chen, Debadeepta Dey
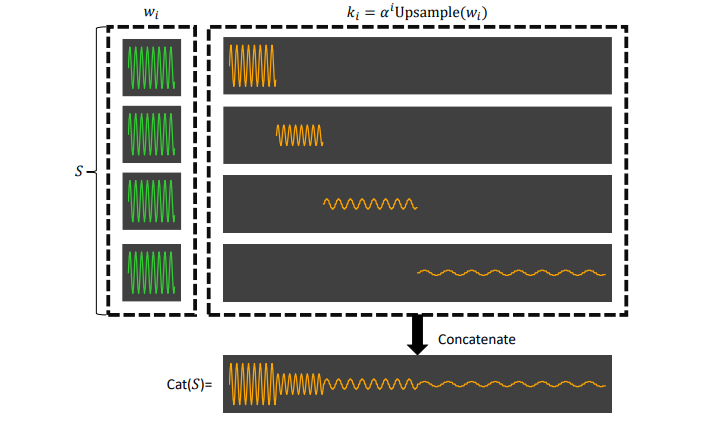
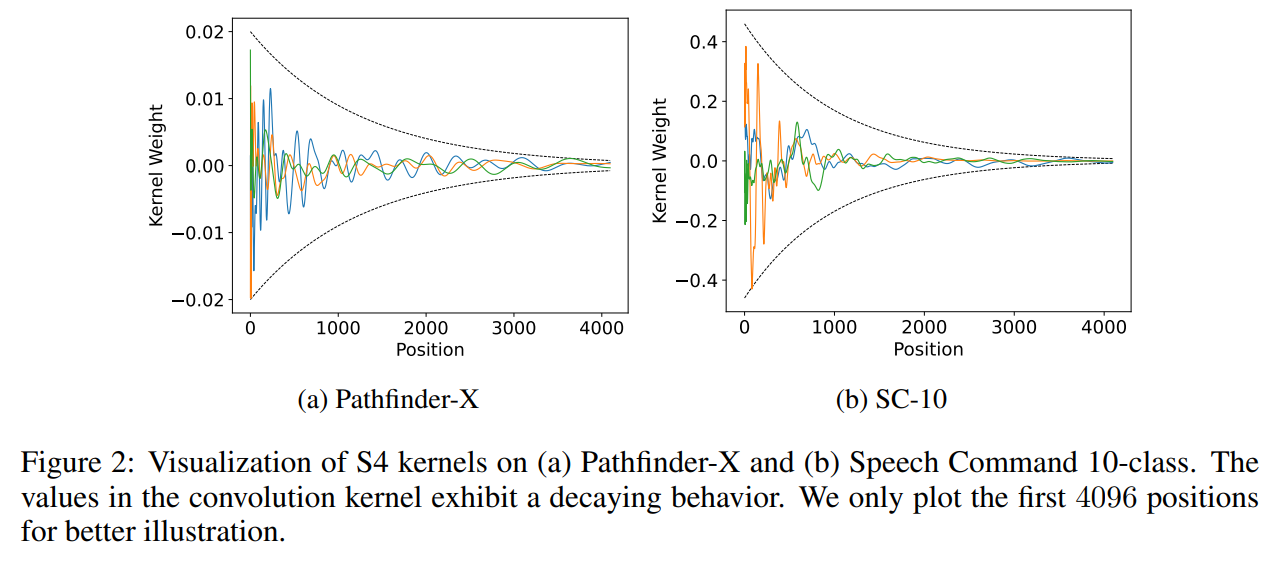
Highlight: We find two simple principles behind the success of global convolutional models on long sequence modeling: 1) Parameterization efficiency; 2) Decaying structure in kernel weights.
(NeurIPS 2021) Do Transformers Really Perform Bad for Graph Representation?
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu
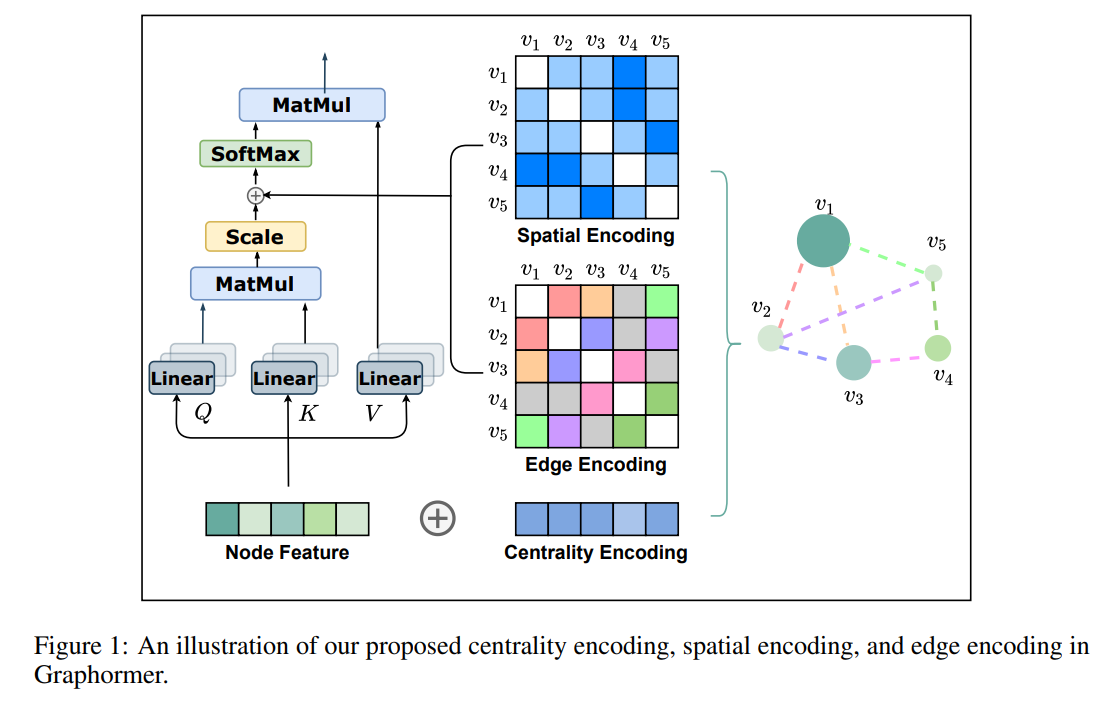
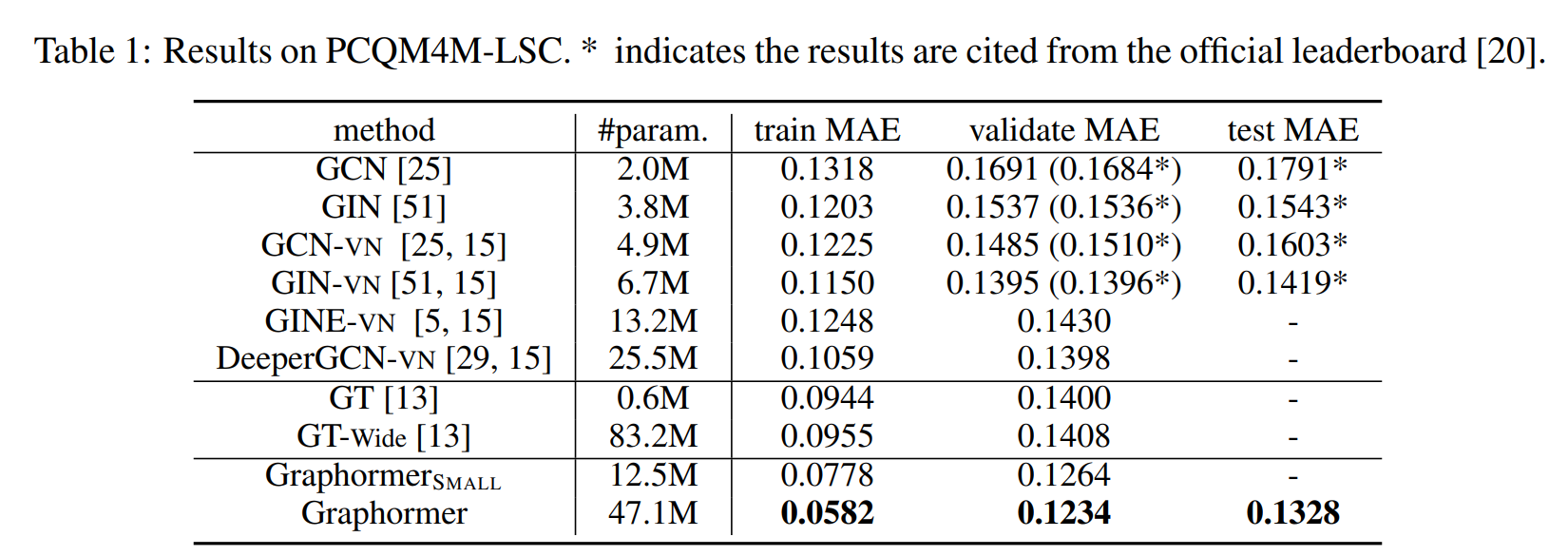
Highlight: Make Transformer great again on graph classification by introducing three graph structural encodings! Achieve SOTA performance on several benchmarks! Winner solution of OGB-LSC challenge!!
(NeurIPS 2021) Towards a Theoretical Framework of Out-of-Distribution Generalization
Haotian Ye, Chuanlong Xie, Tianle Cai, Ruichen Li, Zhenguo Li, Liwei Wang


Highlight: We formulate what an OOD is and derive bounds and model selection algorithm upon our framework.
(NeurIPS 2021) Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
Shengjie Luo, Shanda Li, Tianle Cai, Di He, Dinglan Peng, Shuxin Zheng, Guolin Ke, Liwei Wang, Tie-Yan Liu

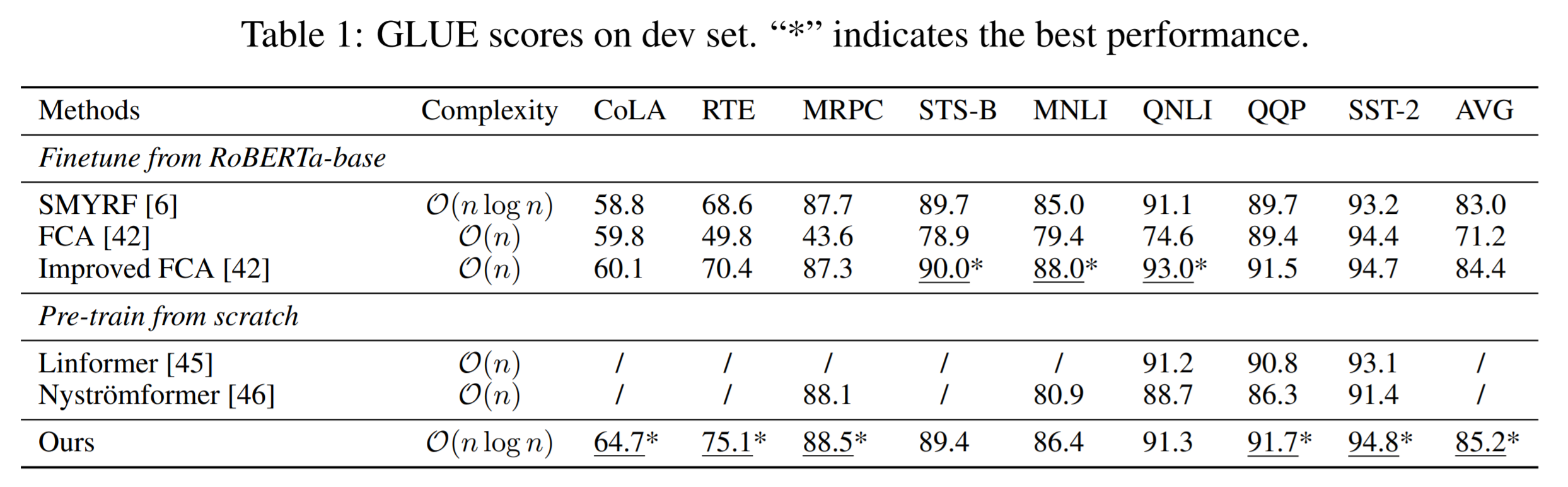
Highlight: Enabling fast relative positional encoding and stabilize the training via Fast Fourier Transform.
(ICML 2021) A Theory of Label Propagation for Subpopulation Shift
Tianle Cai*, Ruiqi Gao*, Jason D. Lee*, Qi Lei*
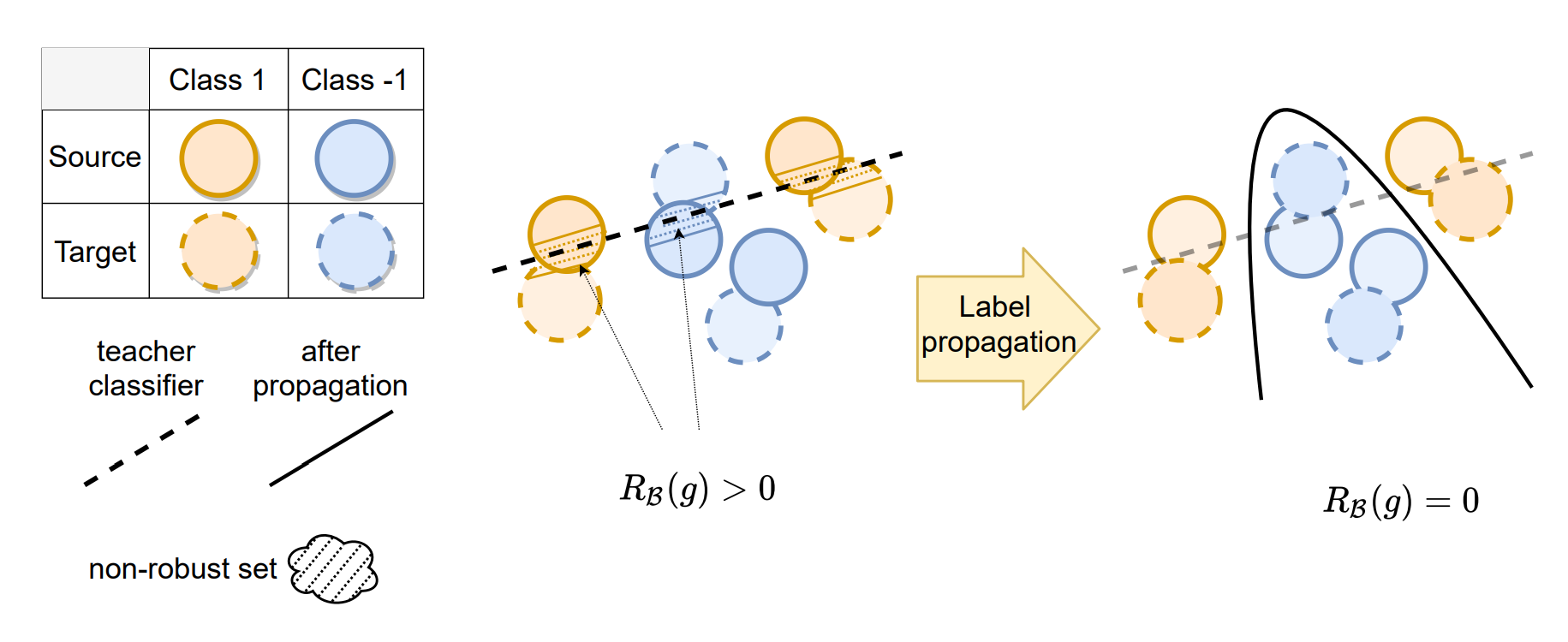
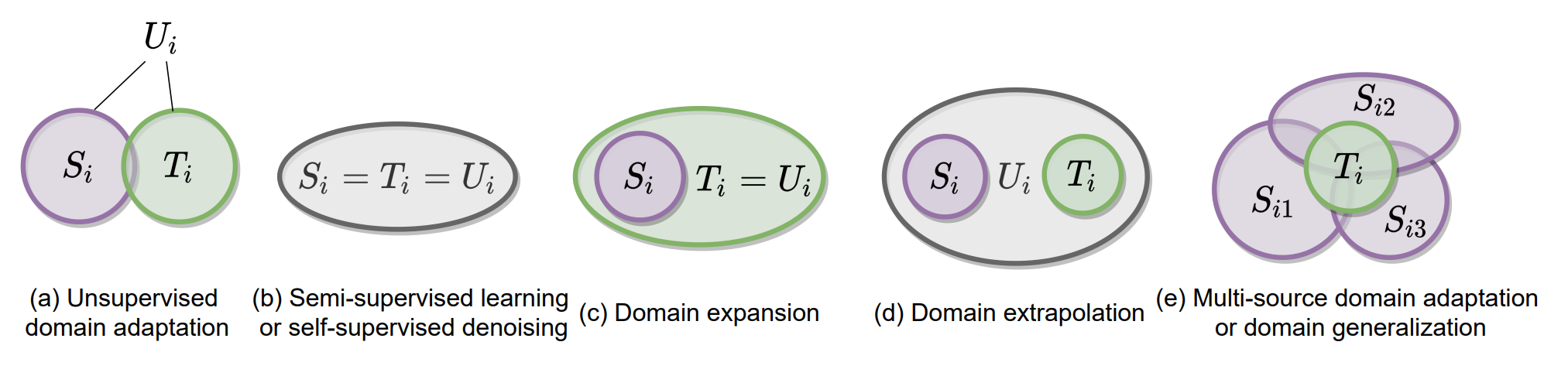
Highlight: Subpopulation shift is a ubiquitous component of natural distribution shift. We propose a general theoretical framework of learning under subpopulation shift based on label propagation. And our insights can help to improve domain adaptation algorithms.
(ICML 2021) Towards Certifying $\ell_\infty$ Robustness using Neural Networks with $\ell_\infty$-dist Neurons
Bohang Zhang, Tianle Cai, Zhou Lu, Di He, Liwei Wang
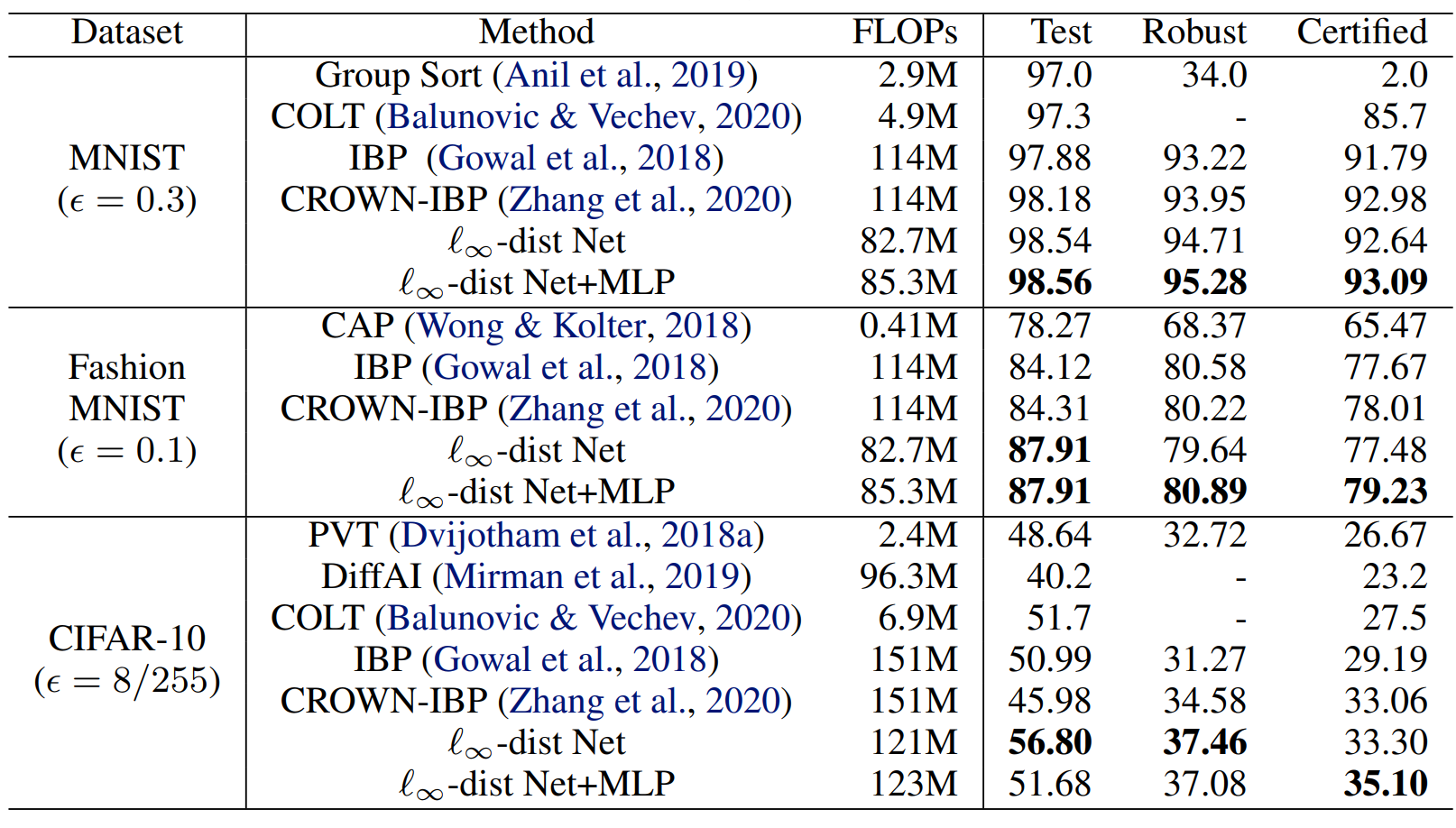
Highlight: New architecture with inherent $\ell_\infty$-robustness and a tailored training pipeline. Achieving SOTA performance on several benchmarks!
[Code]
(ICML 2021) GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
Tianle Cai*, Shengjie Luo*, Keyulu Xu, Di He, Tie-Yan Liu, Liwei Wang
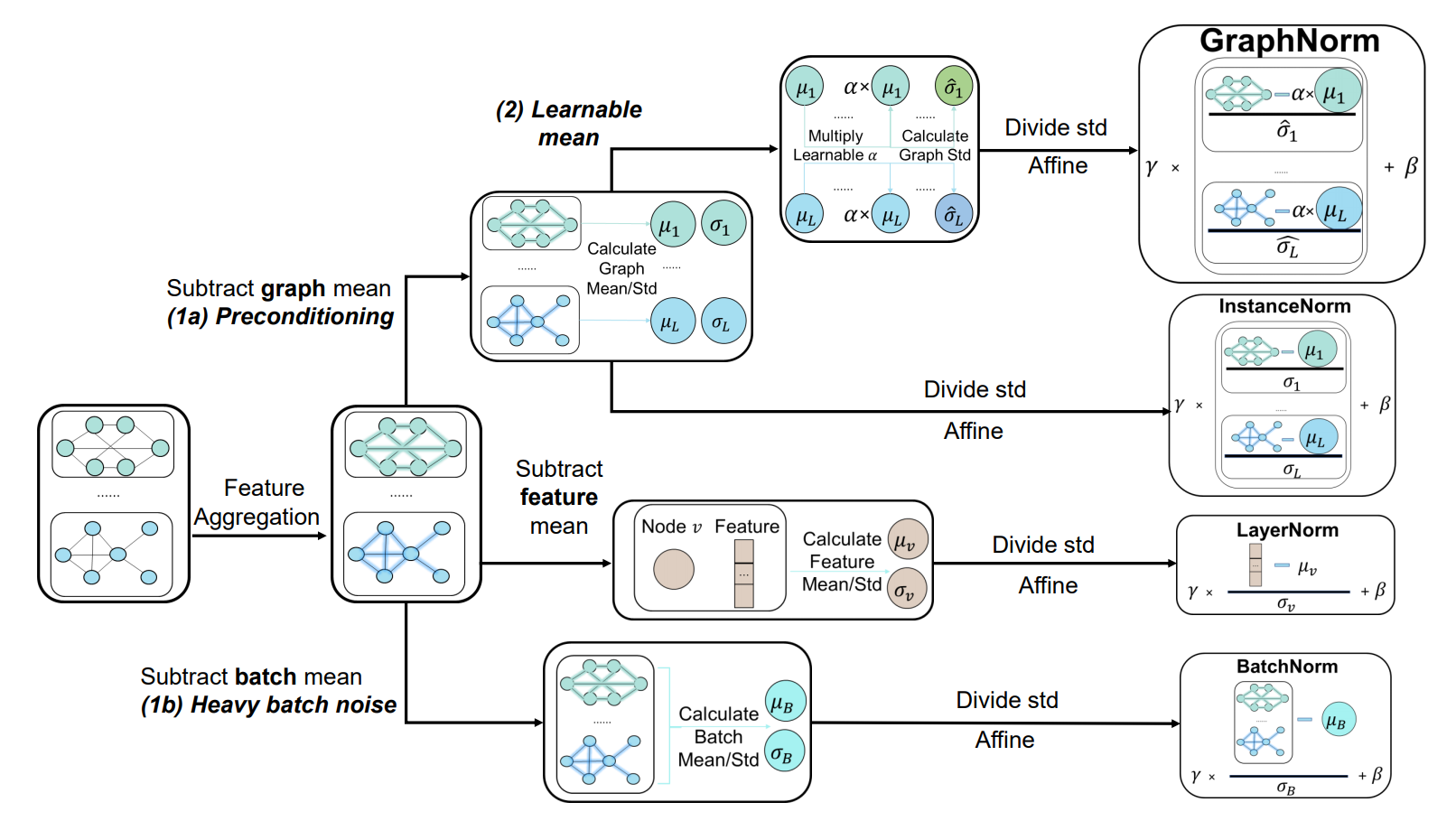
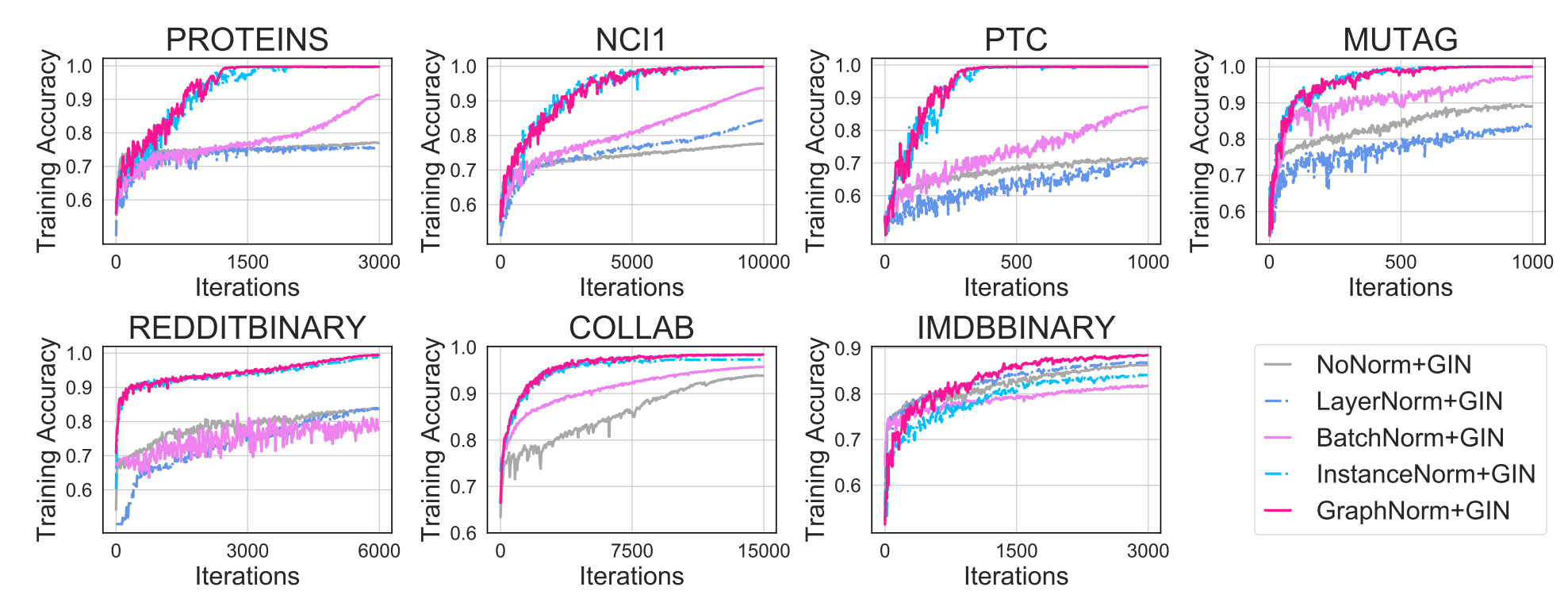
Highlight: A principled normalization scheme specially designed for graph neural networks. Achieve SOTA on several graph classification benchmarks.
[Code], [Third-part implementation by microsoft ptgnn lab. (Thanks for the very quick reaction and implementation MS!)], [Slides]
(NeurIPS 2020) Sanity-Checking Pruning Methods: Random Tickets can Win the Jackpot
Jingtong Su*, Yihang Chen*, Tianle Cai*, Tianhao Wu, Ruiqi Gao, Liwei Wang, Jason D. Lee
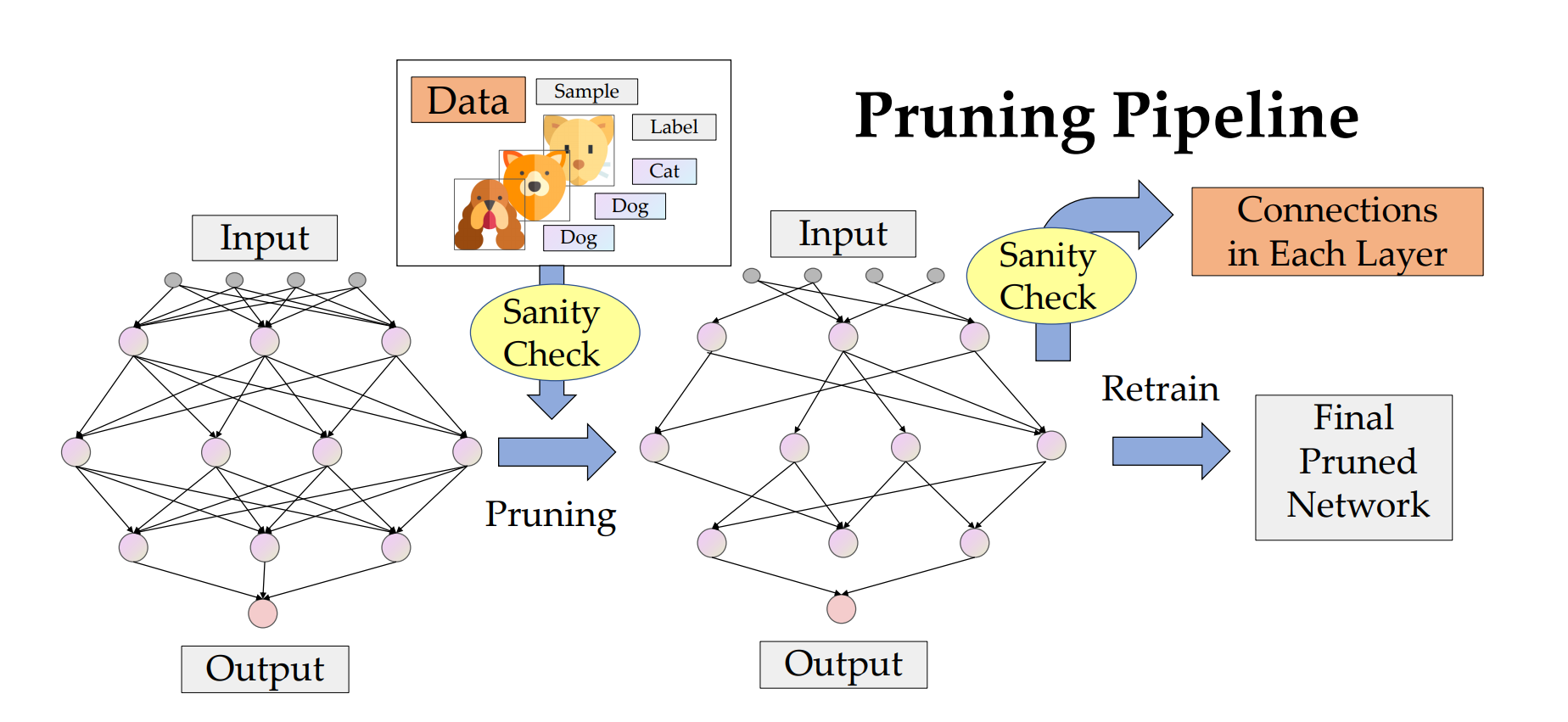
Highlight: We sanity-check several existing pruning methods and find the performance of a large group of methods only rely on the pruning ratio of each layer. This finding inspires us to design an efficient data-independent, training-free pruning method as a byproduct.
[Code]
(NeurIPS 2019 Spotlight 2.4 % Acceptance rate) Convergence of Adversarial Training in Overparametrized Networks
Ruiqi Gao*, Tianle Cai*, Haochuan Li, Liwei Wang, Cho-Jui Hsieh, Jason D. Lee

Highlight: For overparameterized neural network, we prove that adversarial training can converge to global minima (with loss 0).
[Slides]
(NeurIPS 2019 Beyond First Order Method in ML Workshop) Gram-Gauss-Newton Method: Learning Overparameterized Neural Networks for Regression Problems
Tianle Cai*, Ruiqi Gao*, Jikai Hou*, Siyu Chen, Dong Wang, Di He, Zhihua Zhang, Liwei Wang


Highlight: A provable second-order optimization method for overparameterized network on regression problem! As light as SGD at each iteration but converge much faster than SGD for real world application.
Talks
Towards Understanding Optimization of Deep Learning at IJTCS [slides] [video]
A Gram-Gauss-Newton Method Learning Overparameterized Deep Neural Networks for Regression Problems at PKU machine learning workshop [slides]
Experience
- Visiting Research Student at Simons Institute, UC Berkeley
- Program: Foundations of Deep Learning
- June, 2019 - July, 2019
- Visiting Research Internship at MIT
- Advisor: Professor Sasha Rakhlin
- June, 2019 - Sept., 2019
- Visiting Research Student at Princeton
- Host: Professor Jason D. Lee
- Sept., 2019 - Oct., 2019
Conference Services
Reviewer:
- NeurIPS: 2021
- ICML: 2021
- ICLR: 2022
- COLT: 2021
- AISTATS: 2021